Pipelining is the method of a pc processor executing pc directions as separate levels. The pipeline is a logical pipeline that lets the processor carry out an instruction in a number of steps. A number of directions could be within the pipeline concurrently in numerous levels. The processing occurs in a steady, orderly, considerably overlapped method.
In computing, pipelining is often known as pipeline processing. It’s generally in comparison with a producing meeting line wherein totally different product elements are assembled concurrently, despite the fact that some elements may need to be assembled earlier than others. Even with some sequential dependency, many operations can proceed concurrently, facilitating time financial savings.
Take into account a automotive manufacturing unit. With out pipelines, the manufacturing unit can solely work on one automotive at a time. With an meeting line, totally different stations can work on totally different vehicles concurrently. One automotive can have the engine put in, one other the doorways placed on, whereas a 3rd is painted. Working this manner tremendously will increase the variety of vehicles that may be completed.
Laptop processor pipelines work like manufacturing unit meeting strains. Take into account the straightforward instruction “add A + B and put the lead to C.” First, the reminiscence administration unit (MMU) will get the worth A and worth B. Then, the arithmetic-logic unit (ALU) provides them collectively. Lastly, the MMU shops the brand new worth in C. Whereas the ALU provides A and B, the MMU can work on one other operation, like getting worth D.
Pipelining creates and organizes a pipeline of directions the processor can execute in parallel.
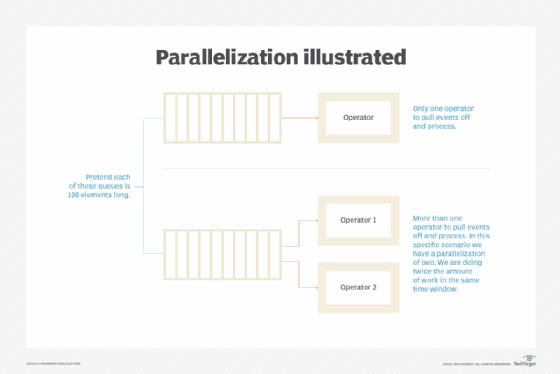
Creating parallel operators to course of occasions is environment friendly. The pipeline is split into logical levels linked to one another to kind a pipelike construction. Directions enter from one finish and exit from the opposite.
Pipelining is an ongoing, steady course of wherein new directions, or duties, are added to the pipeline, and accomplished duties are eliminated at a specified time after processing completes. The processor executes all of the duties within the pipeline in parallel, giving them the suitable time based mostly on their complexity and precedence. Any duties or directions that require processor time or energy because of their measurement or complexity could be added to the pipeline to hurry up processing.
How pipelining works
With out a pipeline, a processor would get the primary instruction from reminiscence and carry out the operation it requires. It will then get the following instruction from reminiscence and so forth. Whereas fetching the instruction, the arithmetic a part of the processor is idle; it should wait till it will get the following instruction. This delays processing and introduces latency.
With pipelining, the following directions could be fetched whereas the processor is performing arithmetic operations. These directions are held in a buffer or register near the processor till the operation for every instruction is carried out. This staging of instruction fetching occurs constantly, rising the variety of directions accomplished in a given interval.
Inside the pipeline, every job is subdivided into a number of successive subtasks. A pipeline part is outlined for every subtask to execute its operations. Every stage or section receives its enter from the earlier stage, then transfers its output to the following. The method continues till the processor has executed all directions and all subtasks are accomplished.
Within the pipeline, every section consists of an enter register that holds knowledge and a combinational circuit that performs operations. The output of the circuit is utilized to the enter register of the following section. Listed here are the steps within the course of:
- Fetch directions from reminiscence.
- Learn the enter register.
- Decode the instruction.
- Execute the instruction.
- Entry an operand in knowledge reminiscence.
- Write the consequence into the enter register of the following section.
Kinds of pipelines
There are two kinds of pipelines in pc processing.
Instruction pipeline
The instruction pipeline represents the levels wherein an instruction is moved by way of the varied segments of the processor: fetching, buffering, decoding and executing. One section reads directions from reminiscence, whereas concurrently, earlier directions execute in different segments. Since these processes occur in an overlapping method, system throughput will increase. The pipeline’s effectivity could be elevated by dividing the instruction cycle into equal-duration segments.
Arithmetic pipeline
The arithmetic pipeline represents the elements of an arithmetic operation that may be damaged down and overlapped as carried out. It may be used for arithmetic operations, like floating-point operations, multiplication of fixed-point numbers, and so on. Registers retailer any intermediate outcomes which might be then handed to the following stage.
Benefits of pipelining
The most important benefit of pipelining is decreasing the processor’s cycle time. It could course of extra directions concurrently, whereas decreasing the delay between accomplished directions. Though pipelining does not cut back the time taken to carry out an instruction — this might nonetheless depend upon its measurement, precedence and complexity — it will increase throughput. Pipelined processors often function at a better clock frequency than the RAM clock frequency. This makes the system extra dependable and helps international implementation.
Doable points in pipelines
Whereas helpful, processor pipelines are liable to sure issues that may have an effect on system efficiency and throughput.
Knowledge dependencies
An information dependency occurs when an instruction in a single stage relies on the outcomes of a earlier instruction, however that consequence just isn’t but obtainable. This happens when the wanted knowledge has not but been saved in a register by a previous instruction as a result of that instruction has not but reached that step within the pipeline.
Because the required instruction has not been written but, the next instruction should wait till the required knowledge is saved within the register. This ready causes the pipeline to stall. In the meantime, a number of empty directions, or bubbles, go into the pipeline, additional slowing it down.
The info dependency drawback can have an effect on any pipeline. Nevertheless, it impacts lengthy pipelines greater than shorter ones as a result of within the former, it takes longer for an instruction to achieve the register-writing stage.
Branching
Department directions could be problematic in a pipeline if a department is conditional on the outcomes of an instruction that has not but accomplished its path by way of the pipeline. If the current instruction is a conditional department, and its consequence will result in the following instruction, the processor won’t know the following instruction till the present instruction is processed. That is why it can not determine which department to take — the required values should not written into the registers.
Different potential points throughout pipelining
Pipelines also can endure from issues associated to timing variations and knowledge hazards. Delays can happen because of timing variations amongst pipeline levels. It’s because totally different directions have totally different processing instances. Knowledge-related issues come up when a number of directions are in partial execution and so they all reference the identical knowledge, resulting in incorrect outcomes. A 3rd drawback is interrupts, which have an effect on instruction execution by including undesirable directions into the instruction stream.
Safety implications in pipelining
Pipelining tries to maintain as a lot knowledge as potential transferring by way of the processor without delay. Generally, knowledge from totally different applications is in numerous levels of the pipeline on the similar time. Attackers can attempt to abuse this to achieve unauthorized knowledge entry. Some examples of this are the {hardware} vulnerabilities Spectre and Meltdown, which may allow attackers to abuse speculative execution to entry knowledge within the pipeline earlier than it completes execution.
Downfall assaults learn processor pipeline caches after they shouldn’t be in a position to. Intel refers to these kinds of assaults as microarchitectural knowledge sampling, or MDS.
Superpipelining and superscalar pipelining
Superpipelining and superscalar pipelining are methods to extend processing velocity and throughput.
Superpipelining means dividing the pipeline into shorter levels, which will increase its velocity. The directions happen on the velocity at which every stage is accomplished. For instance, in a pipeline with seven levels, every stage takes about one-seventh of the period of time required by an instruction in a nonpipelined processor or single-stage pipeline. In idea, it could possibly be seven instances sooner than a pipeline with one stage and is unquestionably sooner than a non-pipelined processor.
Superscalar pipelining means a number of pipelines work in parallel. This may be executed by replicating the inner elements of the processor, which allows it to launch a number of directions in some or all of its pipeline levels.
CPU and GPU pipelining
Any processor sort, together with central processing models (CPUs) and graphics processing models (GPUs), can use instruction pipelining. Due to the variations within the design, the pipelines are tuned in another way. Listed here are the important thing variations:
CPU pipelines
- Extremely parallel in pipeline models and execution.
- Normal use for a lot of perform sorts.
- Deep, multistage pipelines.
- Assist department prediction.
GPU pipelines
- Extremely parallel in variety of processing models.
- Optimized for graphics and math.
- Shallow pipeline depth.
- Normally not designed for department prediction.
Study parallel processing; discover how CPUs, GPUs and knowledge processing models differ; and perceive multicore processors. The time period pipeline can also be utilized in different contexts, akin to an information pipeline, gross sales pipeline, expertise pipeline and code pipeline.
…………………………………………
Sourcing from TechTarget.com & computerweekly.com
DYNAMIC ONLINE STORE
Subscribe Now



Leave a Reply